- In my earlier question, you wrote:
The reason is that if the data is actually baked into the grid graph then some other machinery can use that to optimize queries. For example queries of the type “Is this point reachable from that point” (which is used before every path calculation).
This sounds very similar to Hierarchical Pathfinding A* (HPA*). Does the system calculate all of this automatically if I were to just use the first method (modifying graph data in place), and then the system would automatically calculate and mark specific “areas” (probably using floodfill?) and check if they’re connected before even trying to pathfind, or is this something that I have to do myself using Grid graph rules?
- Do custom
ITraversalProviders use the existing grid graph data, or do they calculate EVERYTHING on their own from scratch?
Example: I change the grid data and mark one position as unwalkable. Then when trying to do simple pathfinding with the default ITraversalProvider, he’s probably going to see which squares are walkable and unwalkable from the existing data, and is simply going to calculate a path (which I assume is faster).
On the other hand, if I use a custom ITraversalProvider, he is going to ignore the existing graph data, and every time a pathfind is requested, he is going to have to calculate his own version of the data (which tiles are walkable and which aren’t) AND actually find a path through those.
Is this correct, or did I misunderstand how this works?
Hi
It’s similar to hierarchical pathfinding, though it doesn’t actually use hierarchical pathfinding to do the actual path calculations. You can find a lot of details here: https://www.arongranberg.com/astar/documentation/dev_4_3_41_5623d52b/hierarchicalgraph.html
The system checks if the destination node can be reached from the start node before it tries to calculate the path. In fact, when searching for the destination node it will try to find the closest node to the given destination that is still reachable from the start node.
When using grid graph rules the hierarchical graph will take those into account out of the box. This is because the grid graph rules affect the actual graph data.
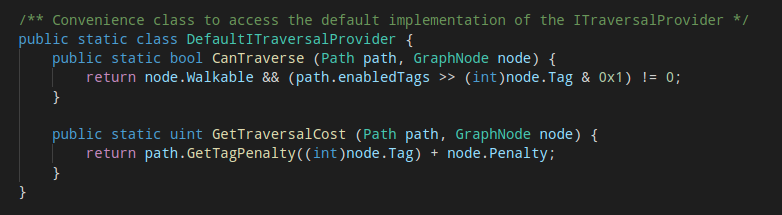
- A custom ITraversalProvider is layered on top of the existing graph structure. What happens is that the A* algorithm visits a lot of nodes. When it visits a node it needs to check each of its neighbours to see if they should be visited as well. As a part of this it will check if the neighbour node is traversable. By default this is done by checking if the node is walkable and if the node’s tag is also traversable by that path. What an ITraversalProvider does is simply to replace that traversability check. Using this ITraversalProvider is equivalent to not using an ITraversalProvider at all (because it just does the same thing):
Note that a hierarchical graph is only calculated for the static graph data, not for an ITraversalProvider.
Usually you use an ITraversalProvider to make small adjustments to an existing graph. For example in a turn based game you usually do not want the agents to be able to walk through other units, but you want a unit to be able to walk on the node it is currently standing on. So you can mark the nodes for all other units as unwalkable in the graph very efficiently.